
Efficient transaction processing is crucial for organizations managing high transaction volumes. When processing falters, it impacts operational timelines and customer loyalty. A client recently faced a critical version of the above.
A slow, data-driven rules engine was creating a backlog of bill audits, with processing times stretching to multiple seconds per bill. Work was stacking up, with large customers experiencing the largest slowdowns.
Our solution transformed their system, reducing processing times from seconds to hundreds of microseconds (a ~10,000x speed increase). As a bonus, it also made debugging rule-related errors significantly easier. Here’s how a paradigm shift courtesy of Event Modeling and Event Sourcing created radical performance increases.
The Problem
The client’s system relied on a CRUD-based user interface allowing them to add/edit rules within a data-driven rules engine. While functional, the system suffered from:
Slow Processing Times: Each bill audit required multiple complex database queries to fetch rules and execute logic, taking multiple seconds per transaction.
Backlog Growth: The delays led to a growing queue of unaudited bills.
Compute Inefficiency: Frequent database access and inefficient runtime processing consumed resources, limiting the system’s throughput.
The Solution
We employed Event Modeling to design a workflow that reimagined the system. The new architecture introduce an event-driven approach, focusing on performance by minimizing runtime database interactions and optimizing rule processing.
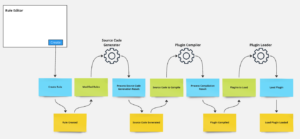
1. Transitioning to Event-Based Architecture.
The existing CRUD-based system was augmented to being the transition into an event-based model. As new rules were created, updated, deleted, or cloned an associated event would be produced in addition to the legacy state changes. These new events initiated a code generation process designed for maximum efficiency and built upon the simple Event Modeling Automation pattern the Todo List.
2. Code Generation Process
A key innovation was shifting database access from runtime to the code generation phase:
- The system loaded all necessary database rows once during code generation.
- These rows were used to generate a C# source code file representing the rule logic.
- Performance was significantly boosted by removing all database access for runtime audit requests.
3. Compilation and Assembly Management
The generated source code was then fed to a new process for dynamic compilation and assembly loading process.
A dedicated process:
- Sequentially added, updated, or removed generated rules to the codebase.
- After each change, the entire set of rules was compiled into a .NET Assembly.
- Upon successful compilation, the assemblies were queued for loading into a ASP.NET MVC web application.
One bonus feature of this design was how it handled some data-related errors in rule definitions. In the previous implementation, such errors would go unnoticed or be surfaced as an error at runtime, often as cryptic messages buried in the logs. With this new approach, many data-related errors were transformed into compile-time syntax errors, making these errors must easier to locate and fix.
4. Dynamic Loading via Application Domains
To integrate the compiled assembly without system disruption, assemblies were loaded using a plugin-style architecture popularized in the early days of the .NET Framework.
- Assemblies were loaded into separate Application Domains to provide isolation between the primary web server process and the dynamically compiled and loaded rules assemblies.
- .NET remoting was used to enable intra-process, cross AppDomain communiciation.
- Using this approach allowed us to unload assemblies at runtime and replace them with more freshly compiled rules assemblies while also preventing memory bloat and out-of-memory errors which would occur if continually loaded into the primary web server process.
Results
The new architecture delivered substantial improvements.
- Performance Boost: Processing time for a single bill audit dropped from multiple seconds to hundreds of microseconds.
- Database Efficiency: Eliminated database queries during runtime audit processing.
- Error Handling: Data-related errors were caught as compile-time syntax errors, streamlining the debugging process.
- Memory Management: Efficient loading and unloading of assemblies ensured the system stays within its resource limits of time.
These changes enable the client to clear their backlog quickly and handle more transactions per second, ensuring smoother operations and improved customer satisfaction.
Reflections and Takeways
This project emphasized the power of thoughtful design and technical innovation:
- Rethink Bottlenecks: Performance gains came from shifting database interactions to compile-time, drastically reducing runtime overhead.
- Event Modeling for Clarity: Mapping out the process with Event Modeling enabled a seamless transition from CRUD based model to an event-sourced workflow.
- Compile-Time Reliability: Transforming data-related errors into compile-time syntax issues streamlined issue triage and debugging.
- Dynamic Architectures: Leveraging a Plugin model and Application Domains ensured the system could evolve without sacrificing stability or efficiency.
Organizations and engineering teams grappling with performance issues can draw from this approach. This outcome demonstrates that even legacy systems can achieve high throughput with the right design.
Conclusion
Through Event Modeling and Event Sourcing, we turned a slow, resource-intensive system into a high-performance powerhouse. Processing times dropped from seconds to microseconds, and error handling for user created rules was drastically reduced.
If you’re facing similar challenges, consider how event-based workflows can redefine your systems for competitive advantage. Sometimes, the key to speed isn’t just optimizing what’s there–it’s rethinking the entire process.
Please reach out if you want to know more about Event Modeling, Event Sourcing, and have the need to breath new life into a languishing legacy system.